Baza de date Dem-Ist oferă celor interesaţi accesul la formularele de populaţie tip A sub forma a seturi de date adică a unor transcrieri digitale ale acestor formulare ce reprezintă eşantioane de populaţie. Sperăm ca în viitor să putem încorpora şi imagini ale surselor de arhivă. Până atunci vom explica cum a avut loc alcătuirea seturilor de date.

La baza procesului au stat următoarele principii:
• Integritatea sursei: am dorit să publicăm sursa în întregimea sa;
• Fidelitatea faţă de formatul sursei: am dorit să respectăm cât mai mult formatul tabular al sursei (adică tabelul formularului de recensământ);
• Compatibilitatea ştiinţifică. Ca în orice demers care are ca scop publicarea unei surse istorice, am fost ghidaţi nu doar de intenţia de a acorda acces la sursă, dar şi de nevoia de a face informaţia istorică cât mai uşor de folosit, indiferent de câmpul ştiinţific de interes. Dacă într-o ediţie „tradiţională” de documente istorice sunt necesare instrumente de lucru precum indice sau aparat critic, sursele seriale pun propriile probleme în materie de adaptare ştiinţifică a materialului istoric.
La acestea putem adăuga principii generale care sunt folosite în alcătuirea oricărui set de date, ştiinţific sau de alt fel:
• Uniformitatea tipului înregistrărilor. Altfel spus, pe parcursul întregului set, fiecare rând trebuie să reprezinte acelaşi tip de obiect. În cazul nostru este vorba de persoane: 1 rând = 1 persoană, în toate cazurile.
• Paritatea dintre variabile şi tip de informaţie. Adică: 1 coloană = 1 singur tip de informaţie.
Am încercat pe cât posibil să urmăm toate principiile, deşi uneori ele au intrat în contradicţie unul cu altul, aşa că unele compromisuri au trebuit făcute.
Din sursă a trebuit să separăm corpul principal al formularelor – adică tabelele, de sumarul prezentat la sfârşitul materialului pentru fiecare localitate, acolo unde sunt redate sumele persoanelor şi articolelor pentru localitatea respectivă. Acestea din urmă sunt publicate sub forma unor fişiere separate.
În tabele a trebuit să divizăm artificial coloane care înglobau mai multe aspecte despre cei recenzaţi. Pentru utilizarea optimă a sursei este obligatorie individualizare acestor aspecte în coloane proprii, proces care în acelaşi timp nu alterează înţelegerea informaţiei istorice. Este doar un mod de a-i da coerenţă, fără a-i afecta conţinutul.
Transcrierea
În faza de transcriere am introdus formularele în tabele digitale, transcriind textul din scrierea chirilică a vremii în alfabetul actual.
Tot în această fază am separat formularele de centralizarea făcută de recenzor.

De asemenea, am divizat anumite coloane, după cum am spus mai devreme şi după cum se poate vedea în exemplele de mai jos.
Armonizarea
Operaţiunile din această fază au presupus dublarea conţinutului original (istoric) cu unul standardizat, care să poată fi folosit în analiza ştiinţifică. Aceasta nu implică înlocuirea coloanelor din formular sau a conţinutului transcrierii lor de bază; doar generarea altor coloane în care acest conţinut este coerentizat. De exemplu, în loc să avem mai mulţi termeni pentru statutul de copil faţă de o persoană – băiat, băieţi, fii-său, fiu-său, fecioru său, fii-sa, fata sa, fete, fată – avem un singur termen – „copil” (sexul persoanei este redat într-o variabilă sau coloană separată).
În mare, această fază a presupus:
• Generarea de coloane acolo unde informaţia istorică nu vine sub formă serială (adică nu este structurată sub forma unei coloane tabel). Aceste coloane se referă la informaţie de ordin geografic, administrativ, sau la sexul persoanelor (pentru care nu a fost prevăzută o coloană specială);
• Standardizarea coloanelor existente în formular;
• Crearea de variabile adiţionale, pentru coloanele deja existente, acolo unde simpla lor standardizare nu este de ajuns pentru o prelucrare eficientă a conţinutului. Astfel de coloane se referă la:
◦ Coduri numerice aplicabile persoanei şi a grupurilor din care face parte fiecare persoană (familia nucleară şi gospodăria);
◦ Variabile care au rolul de a semnala calitatea informaţiei din coloana standardizată, sau neregularităţi în procesul de standardizare.
•Utilizarea unui limbaj comun cu cel al cercetătorilor din câmpul larg. Adică, folosirea unor modele şi standarde de codificare.
Modelele folosite până acum în Dem-Ist sunt:
• Aplicarea conceptului de unitate familială corezidentă (vezi mai jos);
• Sistemele de codificare a statutului în gospodărie, vârstei, sexului şi stării civile folosite de proiectul MOSAIC (https://censusmosaic.demog.), la rândul lor inspirate de North Atlantic Population Project şi IPUMS (https://www.nappdata.org/);
• Sistemul de clasificare a ocupaţiilor HISCO (Historical International Standard of Classification of Occupations - https://collab.iisg.nl/web/).
Exemplificare
Am documentat în detaliu întregul proces de digitizare în lucrarea Primele recensăminte moderne româneşti şi căi către digitizarea lor (vezi Publicaţii).
În continuare oferim celor interesaţi exemple vizuale ale felului în care a fost tratată sursa istorică. Vom lua fiecare element în parte al formularului şi vom vedea cum apare el în seturile de date publicate aici.
Mai jos, cu alb, am reprezentat partea din sursă care în setul de date (eşantionul de populaţie) se regăseşte întocmai cum am transcris-o. Coloanele respective au primit nume terminate în „_or”, însemnând „original”.
Cu portocaliu am colorat conţinutul armonizat al setului de date.
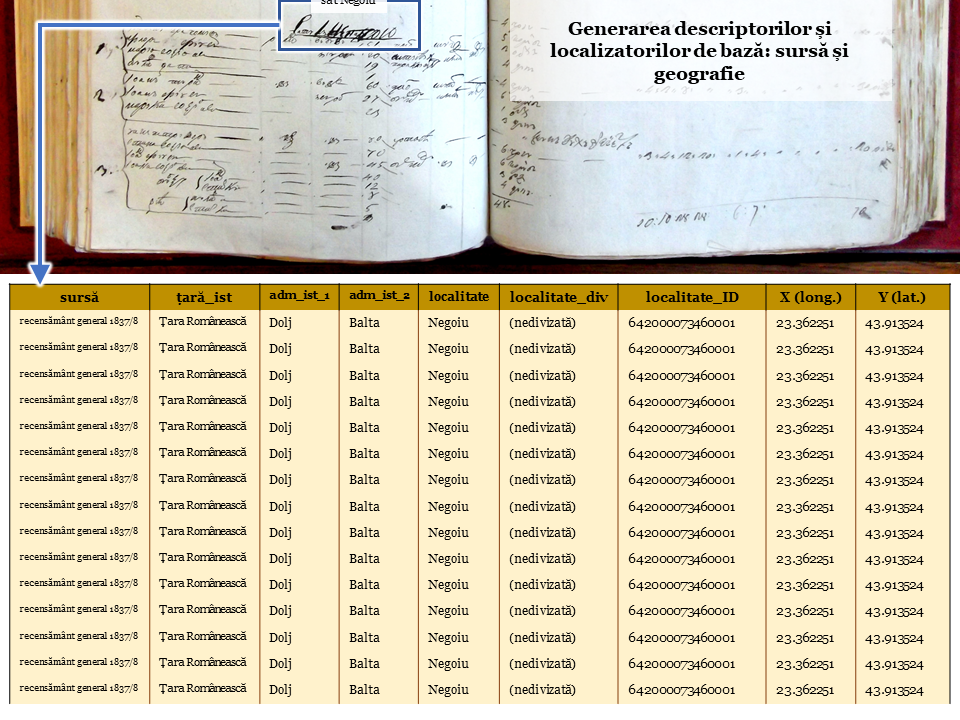
Exemplul nostru se referă la primele trei case din tabelul satului Negoiu din plasa Balta, judeţul Dolj.

În primul rând a trebuit să repertorizăm informaţia din sursa istorică potrivit unor descriptori şi localizatori de bază: denumirea şi anul sursei, ţara istorică, unităţi administrative istorice (în acest caz judeţ şi plasă/plai), diviziuni ale localităţii. Am considerat de asemenea necesar să generăm un cod al localităţii, dar şi să oferim coordonatele geografice pe care le-am identificat pentru localitatea istorică (în format decimal).
Fiecare individ a primit la rândul său un cod numeric unic în toată baza de date.

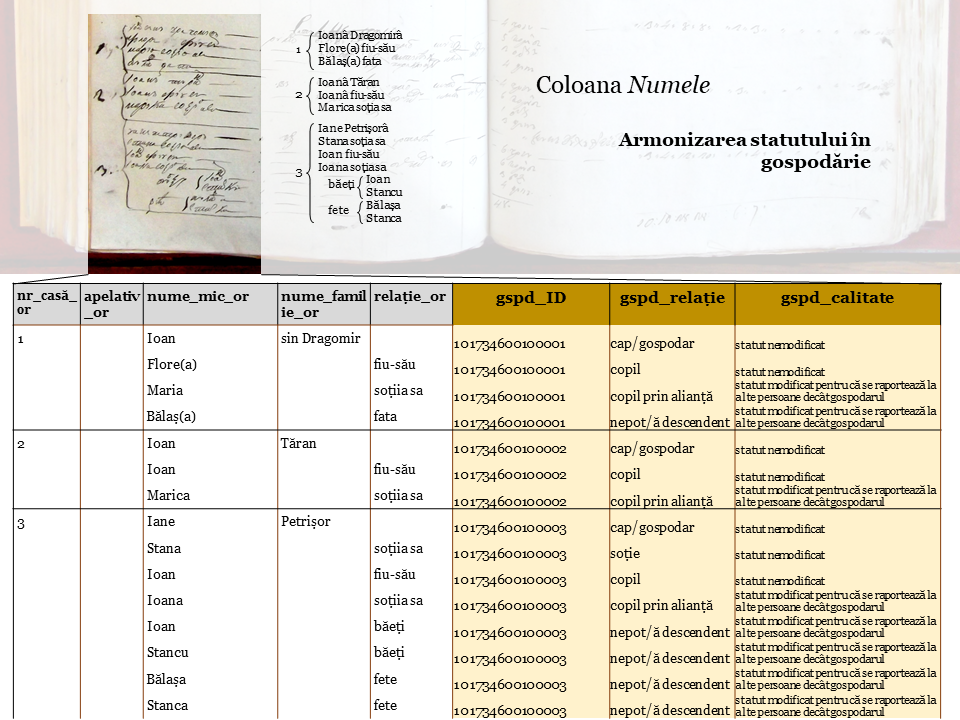
Coloana Numele a fost divizată artificial în patru coloane: apelativ (ex: „popa”, „moş”, „baba”, acolo unde apare), nume de botez, nume de familie, şi relaţia cu persoane din aceeaşi casă. Aceasta din urmă se referă şi la statutul în familia nucleară, dar şi la statutul în gospodărie.
Am armonizat informaţia pentru familia nucleară potrivit unui concept folosit în demografia istorică internaţională, acela de unitate familială corezidentă – UFC (Conjugal Family Unit, sau CFU). 1 UFC = cuplu căsătorit cu/fără copii necăsătoriţi, sau părintele văduv cu copii necăsătoriţi. Fiecare UFC a primit un cod unic în baza de date. Persoanele care nu făceau parte dintr-un UFC au primit de asemenea un cod în aceeaşi variabilă.

La fel am procedat pentru gospodărie, înţeleasă în acest context ca grupul de oameni ce erau grupaţi sub acelaşi număr de casă. Statutul fiecărei persoane a fost raportat la capul de gospodărie (gospodar), după modelul folosit de MOSAIC şi NAPP.
Sexul a fost armonizat după cum urmează.

Etnia este reprezentată în seturile de date prin coloana originală şi două coloane armonizate.

Starea civilă: coloana originală + două coloane armonizate potrivit practicii folosite de MOSAIC şi NAPP.

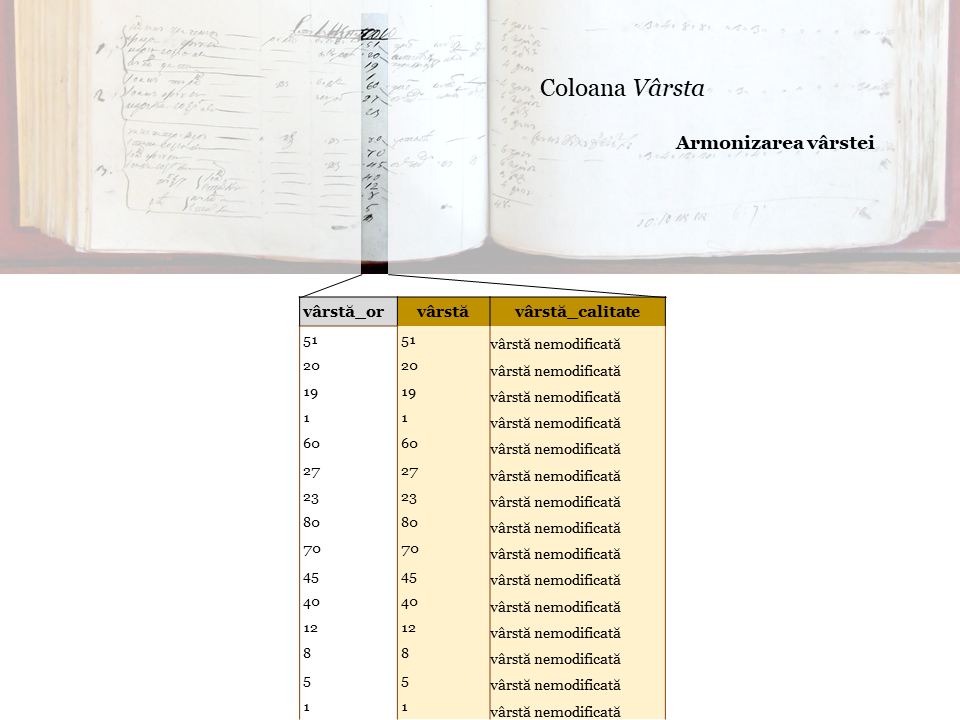
Vârsta este prezentă în seturile de date sub forma coloanei originale şi a două coloane armonizate, urmând modelul MOSAIC/NAPP.
Categoria fiscală a fost mai problematică de armonizat pentru că ea se suprapunea şi peste ocupaţie, şi categorie socială. Am redat coloana originală, dar am armonizat nu doar categoria fiscală, ci şi categoria socială DOAR DACĂ ea se deduce din categoria fiscală.

Statutul rezidenţial a fost redat astfel:

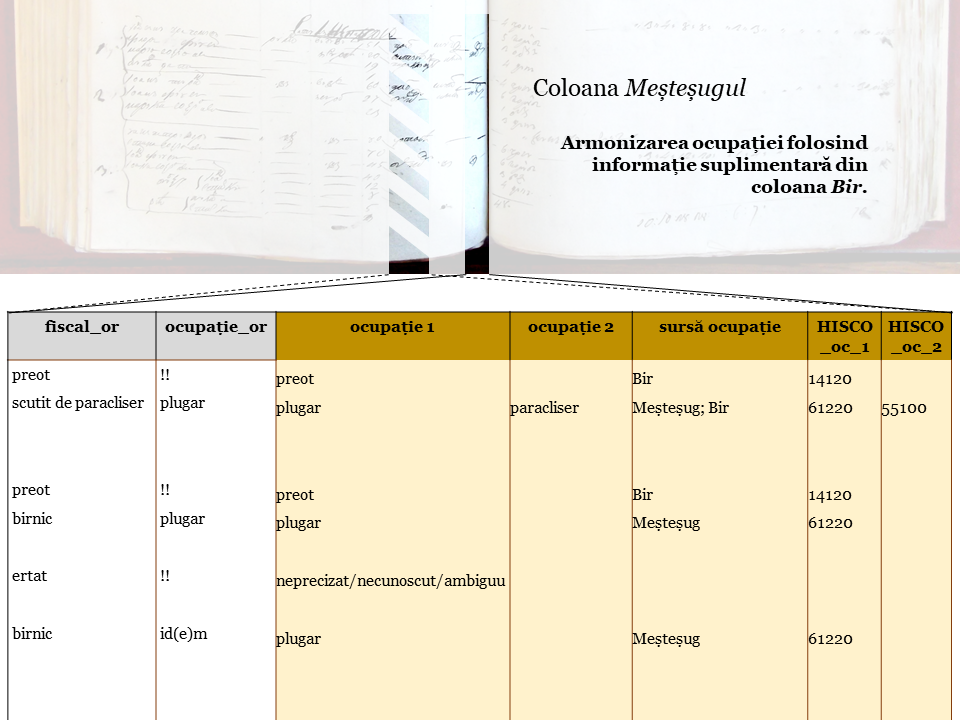
Ocupaţia în recensământ a fost rezervată coloanei Meşteşug, dar ea este prezentă şi în coloana Bir, în funcţie de statutul fiscal al persoanei sau de maniera de înregistrare proprie recenzorilor. Exemplu: dacă unele persoane erau scutite de taxe pentru că erau preoţi, unii recenzori au specificat asta la rubrica Bir, fără a mai trece ocupaţia de preot în rubrica Meşteşug.
Am transcris coloana Meşteşug aşa cum apare în formular, denumind-o „ocupaţie_or”, dar am armonizat ocupaţia preluând conţinutul şi din rubrica Bir, dacă este cazul.
Am creat două astfel de variabile, pentru a acoperi cazurile în care persoana avea două ocupaţii.
De asemenea, am codificat ocupaţia armonizată conform clasificării HISCO.
Pământul folosit a fost redat doar conform transcrierii.

Informaţiile legate de dizabilităţi sunt prezente în coloana originală şi în două coloane armonizate.

Informaţiile legate de celelalte resurse agricole au fost redate întocmai.

În final am inclus o coloană numită „Observaţii”, în care am semnalat aspecte neobişnuite precum citirile nesigure sau alte neregularităţi ale informaţiei istorice care nu au fost redate în variabilele legate de calitate.
Convenţii grafice folosite au fost:
• „!!” – pentru cazuri în care recenzorul nu a scris nimic în spaţiul din formular corespunzător celulei respective din setul de date. Am marcat astfel de spaţii libere în special în două cazuri:
◦ Adulţi care nu au nimic specificat în ceea ce priveşte relaţia faţă de alte persoane, stare civilă, etnie, ocupaţie, categorie fiscală, statut rezidenţial, vârstă;
◦ Copii care nu au nimic specificat în ceea ce priveşte relaţia faţă de alte persoane şi vârsta.
• „(...)” – pentru cazuri în care nu am putut descifra un cuvânt sau mai mult de un cuvânt.
Mai jos, o imagine completă a variabilelor conţinute în eşantioanele de populaţie publicate de Dem-Ist şi a relaţiei lor cu formularul sursei istorice.
.png)